
vaultwarden data should be backed up regularly, preferably via an automated process (e.g., cron job). Ideally, at least one copy should be stored remotely (e.g., cloud storage or a different computer). Avoid relying on filesystem or VM snapshots as a backup method, as these are more complex operations where more things can go wrong, and recovery in such cases can be difficult or impossible for the typical user. Adding an extra layer of encryption on your backups would generally be a good idea (especially if your backup also includes config data like your admin token), but you might choose to skip this step if you're confident that your master password (and those of your other users, if any) is strong.



Backup vaultwarden (formerly known as bitwarden_rs) SQLite3/PostgreSQL/MySQL/MariaDB database by rclone. (Docker)
Jaycuse
I recommend having a read at the wiki
https://github.com/dani-garcia/vaultwarden/wiki/Backing-up-your-vault
I use the docker image bruceforce/bw_backup
My docker compose settings:
bw_backup:
image: bruceforce/bw_backup
container_name: bw_backup
restart: unless-stopped
init: true
depends_on:
- bitwarden
volumes:
- bitwarden-data:/data/
- backup-data:/backup_folder/
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
environment:
- DB_FILE=/data/db.sqlite3
- BACKUP_FILE=/backup_folder/bw_backup.sqlite3
# EVERY DAY 5am
- CRON_TIME=0 5 * * *
- TIMESTAMP=false
- UID=0
- GID=0Once I have the backup file I use borg backup al
Backing up data
By default, vaultwarden stores all of its data under a directory called data (in the same directory as the vaultwarden executable). This location can be changed by setting the DATA_FOLDER environment variable. If you run vaultwarden with SQLite (this is the most common setup), then the SQL database is just a file in the data folder. If you run with MySQL or PostgreSQL, you will have to dump that data separately --
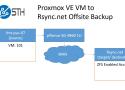
Today we have a quick guide on how to automate Proxmox VE ZFS offsite backups to Rsync.net. The folks at rsync.net set us up with one of their ZFS enabled trial accounts. As the name might imply, Rsync.net started as a backup service for those using rsync. Since then they have expanded to allowing ZFS access for ZFS send/ receive which makes ZFS backups very easy. In our previous article we showed server-to-server backup using pve-zsync to automate the process.
• Backup test
This is very primitive and is unix-centric, but if I rsync from a source to a destination, I will do the following on both:
# find /backup | wc -l
# du -ah /backup | tail -1... and I expect them to be identical (or nearly so) on both ends. Again, very blunt tooling here and this is after a successful, no errors rsync ... but I'm feeling good at that point.

QUICK ANSWER
Backup Android devices using Google One by going to Settings > Google > All services > Backup and toggling on Backup by Google One. You can tap on Back up now if you don't want to wait for your phone to update automatically.
JUMP TO KEY SECTIONS
- How to backup your Android phone with Google
- How to backup your Android phone with Amazon Photos, OneDrive, and others
- Backing up to your computer
- Other options

For C-suite execs and security leaders, discovering your organization has been breached by network intruders, your critical systems locked up, and your data stolen, and then receiving a ransom demand, is probably the worst day of your professional life.
But it can get even worse, as some execs who had been infected with Hazard ransomware recently found out. After paying the ransom in exchange for a decryptor to restore the encrypted files, the decryptor did not work. //
Headley_GrangeSilver badge
"For C-suite execs and security leaders, discovering your organization has been breached, your critical systems locked up and your data stolen, then receiving a ransom demand, is probably the worst day of your professional life."
Third worst, surely.
Second worst is finding out that your bonus is reduced because of it.
First worst is discovering that someone can prove that it's your fault. //
lglethalSilver badge
Go
Paying the Dane Geld
Pay the Geld, and you'll never get rid of the Dane...
What was true so many years ago, remains true to today... //
Doctor SyntaxSilver badge
These guys are just getting ransomware a bad name. //
ThatOneSilver badge
Facepalm
Hope springs eternal
pay the extortionists – for concerns about [obvious stuff]
...Except that you're placing all your hopes on the honesty of criminals!...
Once you've paid them, why would they bother decrypting your stuff? Why wouldn't they ask for even more money, later (or immediately)? Why wouldn't they refrain from gaining some free street cred by reselling all the data they have stolen from you?
Your only hope is that they are honest, trustworthy criminals, who will strive to make sure to repair any damage they've caused, and for whom your well-being is the most important thing in the world...
I think you would be better advised to avoid clicking on that mysterious-yet-oh-so-intriguing link, but that's me. //
3 days
ChrisCSilver badge
Reply Icon
Re: Hope springs eternal
Doesn't matter whether they use the same name or a different one for each victim, the point is that if word gets around that a ransomware group is ripping off people who've paid up, then people are going to be increasingly unlikely to trust any ransomware group.
And at that point, there's a fairly good chance that at least one of the "trustworthy" groups may well decide to take whatever action is needed to deal with this threat to their business model - given the nature of such groups and the dark underbelly of society in which they operate, it's not unreasonable to consider that such action may well be rather permanent to the recipients...
Basic
Free
10 GB
No credit card required
IDrive® Mini
$2.95 per year One user
100 GB
$9.95 per year
500 GB
IDrive® Personal
$99.50/year$69.65 first year
One user, Multiple computers
5 TB Storage
We'd heard of SwissDisk here at rsync.net, but they rarely showed up on our radar screen. We were reminded of their existence a few days ago when their entire infrastructure failed. It's unclear how much data, if any, was eventually lost ... but my reading of their announcement makes me think "a lot".
I'm commenting on this because I believe their failure was due to an unnecessarily complex infrastructure. Of course, this requires a lot of conjecture on my part about an organization I know little about ... but I'm pretty comfortable making some guesses.
It's en vogue these days to build filesystems across a SAN and build an application layer on top of that SAN platform that deals with data as "objects" in a database, or something resembling a database. All kinds of advantages are then presented by this infrastructure, from survivability and fault tolerance to speed and latency. And cost. That is, when you look out to the great green future and the billions of transactions you handle every day from your millions of customers are all realized, the per unit cost is strikingly low.
It is my contention that, in the context of offsite storage, these models are too complex, and present risks that the end user is incapable of evaluating. I can say this with some certainty, since we have seen that the model presented risks that even the people running it were incapable of evaluating.
This is indeed an indictment of "cloud storage", which may seem odd coming from the proprietor of what seems to be "cloud storage". It makes sense, however, when you consider the very broad range of infrastructure that can be used to deliver "online backup". When you don't have stars in your eyes, and aren't preparing for your IPO filing and the "hockey sticking" of your business model, you can do sensible things like keep regular files on UFS2 filesystems on standalone FreeBSD systems.
This is, of course, laughable in the "real world". You couldn't possibly support thousands and thousands of customers around the globe, for nearly a decade, using such an infrastructure. Certainly not without regular interruption and failure.
Except when you can, I guess:
# uptime
12:48PM up 350 days, 21:34, 2 users, load averages: 0.14, 0.14, 0.16(a live storage system, with about a thousand users, that I picked at random)
# uptime
2:02PM up 922 days, 18:38, 1 user, load averages: 0.00, 0.00, 0.00(another system on the same network)
One of the most common pre-sales questions we get at rsync.net is:
"Why should I pay a per gigabyte rate for storage when these other providers are offering unlimited storage for a low flat rate?"
The short answer is: paying a flat rate for unlimited storage, or transfer, pits you against your provider in an antagonistic relationship. This is not the kind of relationship you want to have with someone providing critical functions.
Now for the long answer...
At long last, git is supported at rsync.net.
We wrestled with the decision to add it for some time, as we place a very, very high value on the simplicity of our systems. We have no intention of turning rsync.net into a development platform, running a single additional network service, or opening a single additional TCP port.
At the same time, there are a number of very straightforward synchronization and archival functions inherent to subversion and git that lend themselves very well to our offsite filesystem.

The master paused for one minute, then suddenly produced an axe and smashed the novice's disk drive to pieces. Calmly he said: "To believe in one's backups is one thing. To have to use them is another."
The novice looked very worried.

Every cloud service keeps full backups, which you would presume are meant for worst-case scenarios. Imagine some hacker takes over your server or the building your data is inside of collapses, or something like that. But no, the actual worst-case scenario is "Google deletes your account," which means all those backups are gone, too. Google Cloud is supposed to have safeguards that don't allow account deletion, but none of them worked apparently, and the only option was a restore from a separate cloud provider (shoutout to the hero at UniSuper who chose a multi-cloud solution). //
Google PR confirmed in multiple places it signed off on the statement, but a great breakdown from software developer Daniel Compton points out that the statement is not just vague, it's also full of terminology that doesn't align with Google Cloud products. The imprecise language makes it seem like the statement was written entirely by UniSuper. It would be nice to see a real breakdown of what happened from Google Cloud's perspective, especially when other current or potential customers are going to keep a watchful eye on how Google handles the fallout from this.
Anyway, don't put all your eggs in one cloud basket. //
JohnDeL Ars Tribunus Angusticlavius
8y
6,554
Subscriptor
And this is why I don't trust the cloud. At all.
Always, always, always have a backup on a local computer. //
rcduke Ars Scholae Palatinae
4y
1,715
Subscriptor++
JohnDeL said:
This is why everytime I hear a company talk about moving all of their functions to the cloud, I think about a total failure.
How much does Google owe this company for two weeks of lost business? Probably not enough to matter. //
The master paused for one minute, then suddenly produced an axe and smashed the novice's disk drive to pieces. Calmly he said: "To believe in one's backups is one thing. To have to use them is another."
The novice looked very worried. //
murty Smack-Fu Master, in training
9m
90
Subscriptor++
If you’re not backing up your cloud data at this point, hopefully this story inspires you to reconsider. If you’ve got a boss/CFO/etc that scoffs at spending money on backing up your cloud, link them to this story. ...

A scan of archives shows that lots of scientific papers aren't backed up.
Back when scientific publications came in paper form, libraries played a key role in ensuring that knowledge didn't disappear. Copies went out to so many libraries that any failure—a publisher going bankrupt, a library getting closed—wouldn't put us at risk of losing information. But, as with anything else, scientific content has gone digital, which has changed what's involved with preservation.
Organizations have devised systems that should provide options for preserving digital material. But, according to a recently published survey, lots of digital documents aren't consistently showing up in the archives that are meant to preserve it. And that puts us at risk of losing academic research—including science paid for with taxpayer money. //
The risk here is that, ultimately, we may lose access to some academic research. As Eve phrases it, knowledge gets expanded because we're able to build upon a foundation of facts that we can trace back through a chain of references. If we start losing those links, then the foundation gets shakier. Archiving comes with its own set of challenges: It costs money, it has to be organized, consistent means of accessing the archived material need to be established, and so on.
But, to an extent, we're failing at the first step. "An important point to make," Eve writes, "is that there is no consensus over who should be responsible for archiving scholarship in the digital age."
A somewhat related issue is ensuring that people can find the archived material—the issue that DOIs were designed to solve.
Conclusion
There is a certain disparity between problems and features here: I personally can do without most of the features but do not like to live with the problems. Additionally, backup is a must have but also not something one gets in touch with often as the processes themselves are automated at least to the point that I as a user only call a script (e.g. connect USB drive, call script, disconnect). From that point of view, most of the tools’ advantages are largely uninteresting such as long as there are no problems!
This is an unfortunate situation with backup tools in general which may be one of the reasons why there are so few good tools to chose from :)
Without further delay, the following table summarizes the findings by recalling the greatest issues observed for the respective tools:
Tool Problems
Borg
– very slow especially for initial backups
JMBB
– very slow restore
– no deduplication
– no files above 8 GiB
Kopia
– no Unix pipes/special files support
– large caches in Data-Test
– rather large backup sizes
Bupstash
– large file numbers in single directory
My conclusion from this is that Bupstash is a most viable candidate. There are still some rough edges but given that it is the newest among the tools checked that can be expected.
Traditional backup tools can mostly be subdivided by the following characteristics:
-
file-based vs. image-based
Image-based solutions make sure everything is backed up, but are potentially difficult to restore on other (less powerful) hardware. Additionally, creating images by using traditional tools like dd requires the disk that is being backed up to be unmounted (to avoid consistency issues). This makes image-based backups better suited for filesystems that allow doing advanced operations like snapshots or zfs send-style images that contain a consistent snapshot of the data of interest. For file-based tools there is also a distinction between tools that exactly replicate the source file structure in the backup target (e.g. rsync or rdiff-backup) and tools that use an archive format to store backup contents (tar). -
networked vs. single-host
Networked solutions allow backing up multiple hosts and to some extent allow for centralized administration. Traditionally, a dedicated client is required to be installed on all machines to be backed up. Networked solutions can act pull-based (server gets backups from the clients) or push-based (client sends backup to server). Single-Host solutions consist of a single tool that is being invoked to backup data from the current host to a target storage. As this target storage can be a network target, the distinction between networked and single-host solutions is not exactly clear. -
incremental vs. full
Traditionally, tools either do an actual 1:1 copy (full backup) or copy “just the differences“ which can mean anything from “copy all changed files” to “copy changes from within files”. Incremental schemes allow multiple backup states to be kept without needing much disk space. However, traditional tools require that another full backup be made in order to free space used by previous changes.
Modern tools mostly advance things on the incremental vs. full front by acting incremental forever without the negative impacts that such a scheme has when realized with traditional tools. Additionally, modern tools mostly rely on their own/custom archival format. While this may seem like a step back from tools that replicate the file structure, there are numerous potential advantages to be taken from this:
-
Enclosing files in archives allows them and their metadata to be encrypted and portable across file systems.
-
Given that many backups will eventually be stored to online storages like Dropbox, Mega, Microsoft One Drive or Google Drive, the portability across file systems is especially useful. Even when not storing backups online, portability ensures that backup data can be copied by easy operations like cp without damaging the contained metadata. Given that online stores are often not exactly trustworthy, encryption is also required.
Abstract
This article attempts to compare three modern backup tools with respect to their features and performance. The tools of interest are Borg, Bupstash and Kopia.

BorgTUI -- A simple TUI and CLI to automate your Borg backups :^)