
Crucial early evolutionary step found, imaged, and ... amazingly ... works
Computer History Museum software curator Al Kossow has successfully retrieved the contents of the over-half-a-century old tape found at the University of Utah last month.
UNIX V4, the first ever version of the UNIX operating system in which the kernel was written in the then-new C programming language, has been successfully recovered from a 1970s nine-track tape drive. You can download it from the Internet Archive, and run it in SimH. On Mastodon, "Flexion" posted a screenshot of it running under SGI IRIX.
https://archive.org/details/utah_unix_v4_raw //
The very first version of Unix, later known as the "Zeroth edition", was hand-coded in assembly language by Thompson in 1969. He wrote it for a spare PDP-7 at Bell Labs, a Digital Equipment Corporation minicomputer from 1965. The PDP-7 was an 18-bit machine: it handled memory in 18-bit words. This was so long ago that things like the eight-bit byte had not yet been standardized. PDP-7 UNIX was reconstructed from printouts between 2016 and 2019.
It did well enough that a few years later, Thompson got his hands on a PDP-11. Thompson rewrote his OS for this 16-bit machine – still in assembly language – to create UNIX First Edition. At first, the machine had a single RS11 hard disk, for a grand total of half a megabyte of storage, although the rebuilt source code is from a later machine with a second hard disk.


All the mainstream distros (Ubuntu and Mint, openSUSE and Gecko Linux, Fedora, Debian) come with largely the same choice of desktops, and they're all the same. //
I am also not saying that any of these environments are bad. I have my own preferences, but I completely respect that other people have their own. That's fine too.
That is not the purpose of this piece.
What it is asking is: why are they all the same?
So many different implementations of the "traditional" (since 1995) taskbar-and-launch-menu are not different desktops.
Yes, there are differences, but they are trivial and cosmetic. //
The hidden price of duplicated effort
A very important aspect of this is accessibility. Not only for blind users, but they make a good example. GNOME 2 was reasonably good for people without eyesight, but it's gone, and none of its inheritors come close to matching it.
An excellent and very simple test of accessibility is to use a desktop PC and just unplug the mouse. Windows remains highly usable with only a keyboard. As standard, without enabling any special accessibility aids, windows can be opened, moved, resized, switched and closed, entirely with the keyboard. //
The accessibility features and keyboard controls of macOS are not available at all until enabled, whereas in Windows, they are part of the standard UI, there for everyone to use. //
There are other designs out there. There are more desktops than Windows and macOS, and all offer their own unique benefits. Reimplementing the same old desktop model over and over again doesn't help anyone: it just wastes a huge amount of talent and effort. ® //
Tuesday 17th May 2022 08:55 GMT
DrXymSilver badge
The curse of overchoice
Overchoice is actually a term for when a consumer is given so many options, often varying in ways which are meaningless or confusing that they end up making no choice at all.
Linux has always had that issue and it is illustrated in the article in all the desktops that exist or existed. I expect most prospective Linux users just want to install the thing and use it for something. They really don't care what desktop is powering their experience providing it is easy to use, discoverable, familiar, doesn't throw any nasty surprises at them and lets them get on and do stuff.

There are an almost ridiculous number of Windows-style desktops on Linux – and mostly this applies to the BSDs, too. Most of them are implemented in C, and most use various versions of the Gtk toolkit for their widgets: menus, dialog boxes, buttons and so on.
In approximate age order, the ones still being maintained today are Xfce; MATE, which is a fork of GNOME 2; LXDE; Linux Mint's Cinnamon; and Budgie, implemented in the GNOME-centric Vala language. //
Now we're up to 23. We could dig deeper, but we hope that we've made the point by now. There are several different languages here (but a lot fewer than 23 of them), and several different graphical toolkits (but again, well under 20). This is a vast amount of effort spent reinventing, and then maintaining, the basic concept of a round thing on the end of an axle.
But the underlying concept here is really quite a simple one. The window managers can't match the functionality of the Windows 95 Explorer, and not one of the desktops captures the simple elegance of the original. Windows 95 let you put the taskbar on any screen edge, but you only got one, and you couldn't change its length, or re-arrange or resize its contents, let alone change their orientation. Multiple rows was your only option. //
Remember the Basics of the Unix Philosophy:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
That 1995 design was simple. The components of the desktop – the task bar, the file manager, the text editor, and so on – don't need to exchange lots of rich, complex messages. //
Nearly two dozen different Windows-like UIs represents a titanic waste of programmer effort, skill, and time. Hundreds, maybe thousands of people, working hard for decades… but all on different projects, meaning that none of them achieve greatness. For an example, look at KDE Plasma's 36 launcher menus.
It is 27 years since the first release of KDE, and I suspect that Microsoft has been laughing all the way to the bank ever since. The FOSS world can do better, and it's time it started to try. ®
admin-tools is available as an AppImage which means "one app = one file", which you can download and run on your Linux system while you don't need a package manager and nothing gets changed in your system. Awesome!
AppImages are single-file applications that run on most Linux distributions. Download an application, make it executable, and run! No need to install. No system libraries or system preferences are altered. Most AppImages run on recent versions of Arch Linux, CentOS, Debian, Fedora, openSUSE, Red Hat, Ubuntu, and other common desktop distributions.
calibre has a binary install that includes private versions of all its dependencies. It runs on 64-bit Intel or ARM compatible machines. To install or upgrade, simply copy and paste the following command into a terminal and press Enter:
sudo -v && wget -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin
sudo apt install libxkbcommon0
rsync -r --ignore-existing --include=*/ --include=*.js --exclude=* source/ destination- -r to recurse into directories,
- --ignore-existing to ignore existing files in destination,
the include and exclude filters mean: include all directories, include all *.js files, exclude the rest; the first include is needed, otherwise the final exclude will also exclude directories before their content is scanned.
Finally, you can add a -P if you want to watch progress, a --list-only if you want to see what it would copy without actually copying, and a -t if you want to preserve the timestamps.
To resize an LVM partition in VirtualBox, first increase the virtual disk size using the command VBoxManage modifyhd <UUID> --resize <new size in MB>. Then, within the virtual machine, use commands like lvextend to expand the logical volume and resize2fs to resize the filesystem.
Resizing LVM Partition in VirtualBox
To resize an LVM partition in a VirtualBox virtual machine, follow these steps:
Step 1: Resize the Virtual Disk
- Shutdown the VM: Ensure your virtual machine is powered off.
- Open Command Line: Navigate to the VirtualBox installation directory.
- Run Resize Command: Use the following command to resize the disk:
VBoxManage modifyhd <UUID> --resize <new size in MB>
Replace<UUID>with your virtual disk's UUID and<new size in MB>with the desired size.
Step 2: Modify the Partition
- Boot the VM: Start your virtual machine.
- Check Current Partitions: Use the command:
df -lh
Identify the partition you want to resize, typically/dev/mapper/ubuntu--vg-ubuntu--lv. - Use fdisk: Run:
fdisk /dev/sda- Type
nto create a new partition. - Use default values for the partition number and first sector.
- Set the last sector to use all available space.
- Type
- Write Changes: Type
wto write the changes.
Step 3: Resize the LVM
- Create Physical Volume: Run:
pvcreate /dev/sdaX
ReplacesdaXwith your new partition fromfdiskabove. - Extend the Volume Group: Use:
vgextend <vg-name> /dev/sdaX
Replace<vg-name>with your volume group name. - Extend the Logical Volume: Run:
lvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv
Step 4: Resize the Filesystem
- Resize the Filesystem: Finally, execute:
resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
After completing these steps, your LVM partition should be successfully resized, allowing you to utilize the additional space.
POV: You’re a sysadmin who set up a one-off Linux machine for an app you needed, and now it’s out of disk space.
You originally spun up a VM, installed a recent Ubuntu OS, and just hit Next, Next, Finish through the guided install. Linux is not your bread and butter, you usually deal in Windows, and you just need to get this done.
Approx Reading Time: 10 minutes
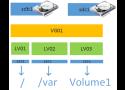
LVM is a volume manager in a Linux platform that helps us to allocate partitions in the system and configure the storage size that will be utilized for a specific volume group. There are some points to be noticed when we work with LVM on VirtualBox to resize our storage.
You can run the calibre server via the command:
/opt/calibre/calibre-server /path/to/the/library/you/want/to/share

Step 1: Add the User to the Sudo Group
First, add the user to the group of sudo by replacing the “vboxuser” with the actual username in the below command:
# sudo usermod -aG sudo [username]
Step 2: Verify the Addition of the User to sudo Group
To verify the successful execution of the above command, list the groups in which “vboxuser” is a part:
# groups vboxuser
Lee DSilver badge
Reply Icon
The primary reason to remove code is maintenance burden.
Every time you want to change some underlying API, or migrate to a new primitive, or introduce new locking, you have a bunch of old code that receives really quite devasting changes that can't be automated... and there's nobody using or maintaining that code to check it still works properly in all possible instances. Then some pillock boots it up on their NAS products as part of their natural firmware upgrades, and it starts trashing customer's NAS data because of some niche side-effect, and now you have a major NAS vendor telling its customers that Linux isn't reliable and just trashed all their customer's filesystems.
As soon as something falls out of active maintenance, it has to be marked for deprecation to let people know not to use it, and if nobody steps up to maintain it, it gets removed.
Lack of maintenance is literally the primary reason for code removal in the Linux kernel. Things that should have been removed decades ago were still actively maintained, so they were allowed to stick around until the last maintainers left (not the last users!). Similarly, things that were brand-new but didn't have adequate maintenance were removed and pushed back out of tree. In fact, one of the main reasons for being refused to be pulled in-tree is that someone then has to maintain it forever. And that's a huge burden for code they may not understand, so it can take DECADES to get code into mainline simply because you have to break it down and get every piece in and slip it past all the maintainers before you ever get close to actually merging the final product, and then you have to prove that enough people will use it so that enough people will be around to maintain it so that kernel maintainers aren't spending half their life trying to fix issues in other people's code that they don't understand.
And this severely affects security. One locking or permission change, and if you don't go updating all your code you are leaving security holes in the kernel. That can't be allowed. And if there's nobody around to say "Yeah, I've fixed bcachefs against this new novel attack that we're seeing throughout the kernel code" then it gets removed. Quite rightly.
People think it's personalities, or technicalities, or some desire to just move into every new thing and throw away every old thing (which is utter nonsense, Linux supports some ridiculously antique stuff still), it's not. It's about maintenance. The one thing Linux lacks is good maintainers with time on their hands to do that job, usually for free! Those are the most valuable and precious resources. And, as things like NTFS filesystem support cough Paragon cough, whole-kernel mass-patches that nobody is willing to break down (cough grsecurity cough) etc. have found out... it doesn't matter how great your code is, if people aren't willing to maintain it you have a decades-long uphill battle to get it into the kernel, let alone keep it there.
Nobody wants to babysit your code in perpetuity, especially if... when a new maintainer is required... not one competent, trusted person is willing to step up and say "I'll do that".

In tcsh, you can do:
(ls $argv > filelist) >& /dev/nullNote that >& redirects both stdout and stderr, but since stdout has already been redirected elsewhere only the stderr will make it through to /dev/null
Check Listening Ports with netstat
netstat is a command-line tool that can provide information about network connections.
To list all TCP or UDP ports that are being listened on, including the services using the ports and the socket status use the following command:
sudo netstat -tunlpThe options used in this command have the following meaning:
-t - Show TCP ports.
-u - Show UDP ports.
-n - Show numerical addresses instead of resolving hosts.
-l - Show only listening ports.
-p - Show the PID and name of the listener’s process. This information is shown only if you run the command as root or sudo user.
Liam Proven(Written by Reg staff) Silver badge
Reply Icon
Re: Justice for bcachefs!
Anyone want to educate me on what bcachefs brings to the party that, say, ext4 doesn't?
I have gone into this at some length before. For instance, here:
https://www.theregister.com/2022/03/18/bcachefs/
... which is linked from the article you are commenting upon.
ext2/3/4 only handle one partition on one disk at a time.
As well as this, first, for partitioning, you need another tool, such as MBR or GPT. But you can do without, in some situations.
For RAID, you need another tool, e.g. kernel mdraid.
(Example of the intersection of 1 & 2: it is normal to make a new device with mdraid and then format that new device directly with ext4, not partitioning it first.)
Want resizable volumes, which might span multiple disks? You need another tool, LVM2.
But don't try to manage mdraid volumes with LVM2, or LVM2 with mdraid. Doesn't work.
Want encryption? You need another tool, such as LUKS. There are several.
Watch out if you use hardware RAID or hardware encryption. The existing tools won't see it or handle it.
It is complicated. There is lots of room for error.
So, ZFS fixed that. It does the partitioning part, and the RAID part, and the encryption part, and the resizing part, and also the mounting part, all in one.
It's great, it's easier and it's faster and you can nominate a fast disk to act as a cache for a bigger array of slower disks...
And it can take snapshots. While it is running. Take an image of your whole OS in a millisecond and then keep running and all the changes go somewhere new. So you can do an entire distribution upgrade, realise one critical tool doesn't work on the new version, and undo the entire thing, and go back to where you were...
While keeping all your data and all your files intact.
All while the OS is running.
And it does it all in one tool.
But it's not GPL so it can't be built into the Linux kernel.
You can load it as a module and that's fine but its cache remains separate from the Linux cache, so it uses twice the memory, maybe more.
So, there are other GPL tools that replicate some of this.
Btrfs does some of it. But Btrfs overlaps with, and does not interoperate with, LVM and with mdraid and with LUKS... and it collapses if the disk fills up... and it's easy to fill up because its "how much free space do I have?" command is broken and lies... and when it corrupts, you can't fix it.
It is, in short, crap, but you can't say that because it is rude and so being the way of Linux it has passionate defenders who complain they are being attacked if you mention problems.
Bcachefs is an attempt to fix this with an all-GPL tool, designed for Linux, which does all the nice stuff ZFS does but integrates better with the Linux kernel. It does not just replace ext4, it will let you replace ext4 and LVM2 and LUKS and mdraid, all in one tool.
It will do everything Btrfs does but not collapse in a heap if the volume fills up. And if it does have problems, you can fix it.
All this is good. All this is needed. We know it's doable because it already exists in a tool from Solaris in a form that FreeBSD can use but Linux can't.
But in a mean-spirited and unfair summary, Kent Overstreet is young and smart and cocky and wants to deliver something better for Linux and Linux users, and the old guard hate that and they hate him. They hate that this smart punk kid has shown up the problems with their tools they've been working on for 20-30 years.
eldakka
Reply Icon
Re: Justice for bcachefs!
Not properly, it doesn't re-stripe the existing data like mdadm or btrfs, it just evens out the disk usage.
A 3 disk raid5 expanded to 5 will inherit the same 50% parity overhead for existing data,
And that can be solved by a simple mv and copy back the file. e.g.
mv $i $i.tmp && cp -p $i.tmp $i && rm $i.tmp
Stick that (or your own preference, using rsync for example) in a simple script/find command to recurse it (with appropriate checks/tests etc.), and that'll make the 'old' data stripe 'properly' across the full RAID width.
eldakka
Reply Icon
Re: Justice for bcachefs!
is as much a "simple solution" and so divorced from the behaviour we'd get if ZFS did the re-striping itself* that you may as well say we don't need ZFS to do snapshots for us, we could write our own simple script to, ooh, create a new overlay/passthrough file system, change all the mount points, halt all processes with writable file handles open... (yes, yes, I'm being hyperbolic).
I never said it shouldn't be something ZFS does transparently. I never said it would be a bad idea or unnecessary thing for ZFS to support.
I was merely pointing out that it is a fairly simple thing to work around such that maybe the unpaid ZFS devs feel they have more important things to work on for now. I mean, it's taken the best part of 20 years to even get the ability to expand a RAIDZ vdev at all.
I'll also say that if anyone actually cares about the filesystem they are using, making conscious decisions to choose a filesystem like ZFS or whatever, then they are not a typical average user. Typical average users don't create ZFS arrays of multiple disks in various raidz/mirror volumes and then grow them. That is not the use-case of an average user.
Later (below) you say "production-ready", why are you messing around with growing raidz vdevs and wanting to re-stripe them to distribute across the array? That is a hobbyist/homelab-type situation. If you are using ZFS in a production environment - that is revenue/income is tied to it - then the answer is to create a new raidz and migrate (zfs-send/receive) data to it. No messing about with growing raidz vdevs and re-striping the data, that's just totally unnecessary.
e.g. 'beneath' the user file access level with no possibility of access control issues,
If you run the mv and cp as root, then there will be no access control issues, cp -p (as root) will preserve file permissions and FACLs.
not risking problems when changing your simplistic commands into production-ready "appropriate check/tests etc" like status reports, running automatically, maybe even backing off when there is a momentary load increase so the whole server isn't bogged down as the recursive cp
If you system gets bogged down from doing a single file copy, then I think you have a system problem.
chews the terabytes,
Why would it chew terabytes? Unless you have TB-sized files, it won't. Recursive doesn't mean what I think you think it means. It does not mean "in parallel". The example I gave will work on a single file at a time in a serial process, and will not move onto the next file until the current file is complete (tehniically it won't move on at all, it's the inner part of a loop you'd need to feed a file list to it). Therefore no extra space beyond the size of the currently being worked on file is needed.
not risking losing track when your telnet into the server shell dies
Why would that do anything? At worst you'll have a single $i.tmp file that you might have to manually do the cp back to the original ($i) name. There will be no data loss (and especially not if you snapshot it first). And even if you 'lose track', just start again, no biggie, will just take longer as you're redoing some of the already done work.
And as I said, you can use things like rsync instead, which would give you the ability to 'keep track' instead. The command I pasted was just the simplest one to give an idea of what is needed, just making a new copy of the file will re-stripe it across the full raidz. Or if you have your pool split up into many smaller filesystems rather than just a single one for the entire pool, then you can zfs-send/receive the filesystem to a enw filesystem in the same pool then use "zfs set mountpoint=<oldmountpoint>) to give the new filesystem the same mountpoint as the old one, then delete the old one.
(not risking a brainfart and doing all that copying over the LAN and back again!) - and simply being accessible to Joe Bloggs ZFS user who just would like it all to work, please.
I agree, it would be. But it doesn't. I'm pointing out that there is a solution to the issue the poster I am replying to mentioned. It is annoying to have to do (I've done it when I changed the recordsize of my filesystems), but it can be done, and it's not particularly difficult.
If someone is going to choose something like ZFS, I'd expect them to be able to do internet searches on topics like this and get help from technical forums or various guides that people have written to cover this sort of use-case. There are guides and instructions on how to do this sort of thing.
Anonymous Coward
Re: Oh I don't want to feel bad
That's because the article is glossing overstreet's persistent refusal to follow basic patch submission procedures, along with his high-handed approach to any criticism of his behaviour or submissions.
The article tries to frame it as a clash of personalities, as if it's an entirely subjective emotional issue on the part of the kernel developers, but the reality is that overstreet is (perhaps deliberately) refusing to conform to the technical requirements for participation. //
wpeckham
Missing the point
Developers made two points here and most comments ignore both.
#1 Development in a company is driven by projects and dollars. Development in the Kernel is driven by community! A toxic member of the community cannot be, and should not be, trusted.
#2 To a developer features are a nice ting to pursue, but the gold standard involves correctness, elegance, and MAINTAINABILITY! You might like that greater feature set, but if it does not integrate with existing code safely or does not present in a way that the other developers can maintain then it is a trap. Using bad or misleading code is to set landmines on your yard. Don't.
Choices must be made, and making them in a way that supports and strengthens the community, the philosophy, the standards, and the product is always the RIGHT choice. Even if you do not like it.
And does it really matter if a feature takes and extra cycle to implement to make sure everyone is happy with it and the way it is implemented? It never really has before, so why now? I am willing to wait for it to be done RIGHT, instead of just fast!

The whole incident emphasizes the extent to which these ostensibly technical debates are often settled by personality and emotion, rather than by technical excellence. //
It looks likely that Overstreet has upset too many important, influential people, and hurt too many feelings — and as a result, Linux is not going to get a new next-gen copy-on-write filesystem. It's a significant technological loss, and it's all down to people not getting along, rather than the shared desire to create a better OS. ®
fortunately, i made a discovery: the “detail” page is called “detail.php”, while the normal “get me the whole image” link is “fetch.php”. so i simply deleted detail.php and symlinked the name to fetch.php; this fixed it, and i didn't even have to edit any code, because doku is built the way it should be: a loose collection of files that anyone can understand.
this is, again, why i went with dokuwiki - because it's one of the last vestiges of classic nerd software on the internet. it's like linux in 2003, before it started trying to Help you, before it started trying to be a mishmash of half-baked, half-remembered ideas from Windows and MacOS that don't make end users all that much more comfortable, while getting in the way of the people who the OS was meant to be for in the first place. just let me ifconfig an IP onto eth0 you jackoffs, stop Managing my Network.
i hate modern linux. it has been going in the wrong direction for over 20 years, trying desperately to suck up to consumers who will never care about it, like the democrats “reaching across the aisle” to people who simply bite their fingers off for their trouble, while doing immense harm to their own constituents in the process. and that's really a microcosm of all free software, it's why every other open source CMS package reeks of business-brain.
enterprise brainworms have taken over so fully that you just can't find something at the triple point of “good idea”, “well maintained” and “actually useful for normal human beings,” which is, again, how i wound up using a piece of software from 2004, before the collapse began in earnest. it's like finding steel that isn't radioactive due to fallout from nuclear tests: you simply have to go dig up the old stuff, even if that means melting down old car chassis.
- The Linux screen command is a versatile tool that allows you to run terminal applications in the background and switch back to them when needed.
- It supports split-screen displays and can be used over SSH connections, even after disconnecting and reconnecting.
- With screen, you can create new windows, run multiple processes, detach and reattach sessions, and share sessions between multiple users in real-time.
With the Linux screen command, you can push running terminal applications to the background and pull them forward when you want to see them. It also supports split-screen displays and works over SSH connections, even after you disconnect and reconnect!